its encoding". "8.2.2.3. Character encodings". HTML 5.1 Standard. W3C. "8.2.2.3. Character encodings". HTML 5 Standard. W3C. "12.2.3.3 Character encodings"...
24 KB (2,454 words) - 05:06, 16 November 2024
commonly used. In order to work around the limitations of legacy encodings, HTML is designed such that it is possible to represent characters from the whole...
22 KB (2,590 words) - 21:13, 10 October 2024

vendor encodings, and Unicode encodings such as UTF-8 and UTF-16. The most popular character encoding on the World Wide Web is UTF-8, which is used in 98...
32 KB (3,919 words) - 00:16, 22 April 2025
In SGML, HTML and XML documents, the logical constructs known as character data and attribute values consist of sequences of characters, in which each...
322 KB (3,512 words) - 19:52, 9 April 2025
multi-byte, stateful, and other non-ASCII-compatible encodings as the basis for percent-encoding, leading to ambiguities and difficulty interpreting URIs...
18 KB (1,684 words) - 18:51, 2 May 2025

Mojibake (redirect from Broken character)
headers; see character encodings in HTML. Mojibake also occurs when the encoding is incorrectly specified. This often happens between encodings that are similar...
60 KB (5,928 words) - 12:12, 2 April 2025
the MIME type (e.g., text/html or application/xhtml+xml) and the character encoding (see Character encodings in HTML). In modern browsers, the MIME type...
84 KB (9,599 words) - 15:09, 29 April 2025
Base64 (redirect from Base64 (encoding scheme))
Base64 Data Encodings, is an informational (non-normative) memo that attempts to unify the RFC 1421 and RFC 2045 specifications of Base64 encodings, alternative-alphabet...
39 KB (3,744 words) - 21:20, 1 April 2025
Charset detection (redirect from Character encoding detection)
label datasets with the correct encoding. See Character encodings in HTML#Specifying the document's character encoding. Even though UTF-8 and UTF-16 are...
5 KB (640 words) - 00:42, 4 January 2025
UTF-8 (redirect from UTF-8 encoded)
invalid input. Character encodings in HTML – Use of encoding systems for international characters in HTML Comparison of Unicode encodings GB 18030 – Official...
49 KB (5,086 words) - 09:51, 19 April 2025

Tab key (redirect from Tab character)
nickgravgaard.com. Retrieved 23 March 2018. See Character encodings in HTML#HTML character references "Character Entity Reference Chart". dev.w3.org. Retrieved...
14 KB (1,941 words) - 00:56, 19 February 2025

ASCII (redirect from ASCII (character encoding))
teleprinter encoding systems. Like other character encodings, ASCII specifies a correspondence between digital bit patterns and character symbols (i.e...
109 KB (8,057 words) - 10:33, 2 May 2025
Unicode (redirect from Unicode Character Set)
Indeed, any two encodings chosen were often totally unworkable when used together, with text encoded in one interpreted as garbage characters by the other...
111 KB (11,524 words) - 07:52, 1 May 2025
justification, those space characters can be used to supplement the electronic formatting when needed. In computer character encodings, there is a normal general-purpose...
26 KB (2,584 words) - 00:29, 18 April 2025
languages at 95% use or usually rather higher. The same encodings are used in local files (or databases), in fact many more, at least historically. Exact measurements...
12 KB (1,330 words) - 22:55, 15 April 2025

Plain text (section Character encodings)
principle, plain text can be in any encoding, but occasionally the term is taken to imply ASCII. As Unicode-based encodings such as UTF-8 and UTF-16 become...
12 KB (1,653 words) - 06:29, 28 March 2025
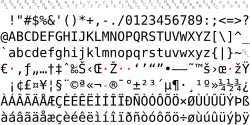
Windows-1252 (category Computer-related introductions in 1985)
multibyte character encodings such as Shift-JIS. As many applications preferred to use 8-bit strings, Windows-1252 remained the most popular encoding on Windows...
40 KB (1,594 words) - 15:39, 21 April 2025
A numeric character reference (NCR) is a common markup construct used in SGML and SGML-derived markup languages such as HTML and XML. It consists of a...
14 KB (1,203 words) - 08:59, 5 February 2025
Latin letters, and some special and control characters as six-bit character codes. Unlike later encodings such as ASCII, BCD codes were not standardized...
25 KB (1,930 words) - 05:22, 12 December 2024

Extended ASCII (redirect from Extended character)
a repertoire of character encodings that include (most of) the original 96 ASCII character set, plus up to 128 additional characters. There is no formal...
15 KB (2,003 words) - 18:31, 12 February 2025
ISO basic Latin alphabet (category All Wikipedia articles written in American English)
other encodings used in Microsoft Windows (some roughly similar to ISO/IEC 8859-1) 1990: Unicode 1.0 (developed by the Unicode Consortium), contained in the...
24 KB (1,638 words) - 17:48, 4 March 2025

UTF-16 (redirect from Supplementary character)
UTF-16 encodings are the only encodings that this specification needs to treat as not being ASCII-compatible encodings. "Encoding Standard". encoding.spec...
36 KB (4,121 words) - 03:42, 27 April 2025
ISO/IEC 8859-9 (category Computer-related introductions in 1989)
coded graphic character sets — Part 9: Latin alphabet No. 5, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition...
21 KB (587 words) - 13:57, 1 January 2025
2.2.3. Character encodings". HTML 5.1 Standard. W3C. "8.2.2.3. Character encodings". HTML 5 Standard. W3C. "12.2.3.3 Character encodings". HTML Living...
8 KB (959 words) - 21:47, 17 December 2024

ISO/IEC 8859-1 (category Character sets)
coded graphic character sets—Part 1: Latin alphabet No. 1, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition...
42 KB (2,273 words) - 00:25, 16 April 2025
Code point (category Character encoding)
See comparison of Unicode encodings for details. Code points are normally assigned to abstract characters. An abstract character is not a graphical glyph...
7 KB (908 words) - 02:59, 2 May 2025

Japanese language and computers (redirect from Japanese character encoding)
embedded in HTML pages. EUC, on the other hand, is handled much better by parsers that have been written for 7-bit ASCII (and thus EUC encodings are used...
14 KB (1,742 words) - 02:31, 10 January 2025
ISO/IEC 2022 (redirect from International Register of Coded Character Sets)
language-specific double-byte encodings or variable-width encodings; some of these (such as the Simplified Chinese encoding GB 2312) conform to ISO 2022...
108 KB (11,115 words) - 01:32, 28 April 2025
UTF-32 (category Character encoding)
actually only 21 bits). In contrast, all other Unicode transformation formats are variable-length encodings. Each 32-bit value in UTF-32 represents one...
13 KB (1,580 words) - 22:49, 26 April 2025