k-means clustering is a method of vector quantization, originally from signal processing, that aims to partition n observations into k clusters in which...
62 KB (7,754 words) - 11:44, 13 March 2025
In data mining, k-means++ is an algorithm for choosing the initial values (or "seeds") for the k-means clustering algorithm. It was proposed in 2007 by...
11 KB (1,403 words) - 04:59, 19 April 2025
clustering (also referred to as soft clustering or soft k-means) is a form of clustering in which each data point can belong to more than one cluster...
14 KB (2,032 words) - 17:33, 4 April 2025
k-medoids is a classical partitioning technique of clustering that splits the data set of n objects into k clusters, where the number k of clusters assumed...
17 KB (1,907 words) - 07:41, 30 April 2025
K-medians clustering is a partitioning technique used in cluster analysis. It groups data into k clusters by minimizing the sum of distances—typically...
6 KB (752 words) - 23:49, 19 June 2025

These clusters then define segments within the image. Here are the most commonly used clustering algorithms for image segmentation: K-means Clustering: One...
75 KB (9,510 words) - 11:41, 24 June 2025
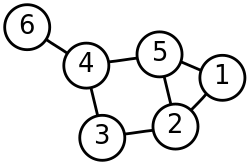
The general approach to spectral clustering is to use a standard clustering method (there are many such methods, k-means is discussed below) on relevant...
27 KB (3,562 words) - 02:56, 14 May 2025
CURE algorithm (redirect from Cure data clustering)
(Clustering Using REpresentatives) is an efficient data clustering algorithm for large databases[citation needed]. Compared with K-means clustering it...
6 KB (788 words) - 18:03, 29 March 2025
co-authored highly cited research papers on nearest neighbor search and k-means clustering. He has published many papers on computer chess, was the local organizer...
4 KB (260 words) - 05:09, 4 May 2025

purpose of K-means clustering is to classify data based on similar expression. K-means clustering algorithm and some of its variants (including k-medoids)...
31 KB (3,567 words) - 04:54, 11 June 2025

Feature learning (section K-means clustering)
K-means clustering is an approach for vector quantization. In particular, given a set of n vectors, k-means clustering groups them into k clusters (i...
45 KB (5,114 words) - 02:41, 2 June 2025
process of actually solving the clustering problem. For a certain class of clustering algorithms (in particular k-means, k-medoids and expectation–maximization...
20 KB (2,763 words) - 23:09, 7 January 2025
BIRCH (redirect from Birch clustering method for large databases)
iterative reducing and clustering using hierarchies) is an unsupervised data mining algorithm used to perform hierarchical clustering over particularly large...
13 KB (2,275 words) - 14:43, 28 April 2025

results. It has been asserted that the relaxed solution of k-means clustering, specified by the cluster indicators, is given by the principal components, and...
117 KB (14,851 words) - 06:44, 17 June 2025
have a low or negative value, then the clustering configuration may have too many or too few clusters. A clustering with an average silhouette width of over...
14 KB (2,220 words) - 20:29, 20 June 2025
similarities between data points, such as clustering and similarity search. As an example, the K-means clustering algorithm is sensitive to feature scales...
8 KB (1,041 words) - 01:18, 24 August 2024
basis for clustering, and ways to choose the number of clusters, to choose the best clustering model, to assess the uncertainty of the clustering, and to...
32 KB (3,525 words) - 20:04, 9 June 2025
singular value decomposition approach. k-SVD is a generalization of the k-means clustering method, and it works by iteratively alternating between sparse coding...
7 KB (1,308 words) - 23:27, 27 May 2024
Automatic clustering algorithms are algorithms that can perform clustering without prior knowledge of data sets. In contrast with other cluster analysis...
13 KB (1,625 words) - 12:02, 20 May 2025
correlation analysis (CCA) techniques as a pre-processing step, followed by clustering by k-NN on feature vectors in reduced-dimension space. This process is also...
32 KB (4,333 words) - 23:48, 16 April 2025
DBSCAN (redirect from Density Based Spatial Clustering of Applications with Noise)
Density-based spatial clustering of applications with noise (DBSCAN) is a data clustering algorithm proposed by Martin Ester, Hans-Peter Kriegel, Jörg...
29 KB (3,492 words) - 22:56, 19 June 2025
Consensus clustering is a method of aggregating (potentially conflicting) results from multiple clustering algorithms. Also called cluster ensembles or...
22 KB (2,951 words) - 05:21, 11 March 2025
computer science, constrained clustering is a class of semi-supervised learning algorithms. Typically, constrained clustering incorporates either a set of...
3 KB (361 words) - 18:57, 26 June 2025
Look up clustering in Wiktionary, the free dictionary. Clustering can refer to the following: In computing: Computer cluster, the technique of linking...
881 bytes (153 words) - 17:30, 10 March 2022
transmission. K-means clustering, an unsupervised machine learning algorithm, is employed to partition a dataset into a specified number of clusters, k, each...
140 KB (15,571 words) - 01:31, 25 June 2025
the minimization of K-means clustering. Furthermore, the computed H {\displaystyle H} gives the cluster membership, i.e., if H k j > H i j {\displaystyle...
68 KB (7,783 words) - 02:31, 2 June 2025
transmission. K-means clustering, an unsupervised machine learning algorithm, is employed to partition a dataset into a specified number of clusters, k, each...
68 KB (7,556 words) - 22:09, 19 May 2025
diagram Rate-distortion function Data clustering Centroidal Voronoi tessellation Image segmentation K-means clustering Autoencoder Deep Learning Part of this...
13 KB (1,649 words) - 10:50, 3 February 2024
Clustering high-dimensional data is the cluster analysis of data with anywhere from a few dozen to many thousands of dimensions. Such high-dimensional...
18 KB (2,284 words) - 11:17, 24 June 2025
similarity search, FAISS provides the following useful facilities: k-means clustering Random-matrix rotations for spreading the variance over all the dimensions...
14 KB (1,163 words) - 11:40, 14 April 2025