LY1 (Y&Y 256 glyph encoding) is an 8-bit TeX encoding developed by Berthold Horn. Mittelbach, Frank; Fairbairns, Robin; Lemberg, Werner (2016-02-18) [1995]...
16 KB (75 words) - 17:56, 25 March 2025

encodings extended existing simple four-bit numeric encoding to include alphabetic and special characters, mapping them easily to punch-card encoding...
31 KB (3,798 words) - 18:25, 5 August 2025

ASCII (redirect from ASCII (character encoding))
for American Standard Code for Information Interchange, is a character encoding standard for representing a particular set of 95 (English language focused)...
108 KB (8,017 words) - 01:16, 3 August 2025
Charset detection (redirect from Character encoding detection)
Character encoding detection, charset detection, or code page detection is the process of heuristically guessing the character encoding of a series of...
6 KB (708 words) - 12:12, 7 July 2025
ISO/IEC 2022 (category Encodings of Asian languages)
4 ("Encoding Methods"), section "EUC encoding" Lunde (2008), pp. 253–255, Chapter 4 ("Encoding Methods"), section "EUC versus ISO-2022 encodings". ISO-IR-196...
108 KB (11,141 words) - 03:25, 21 July 2025
telecommunications industries in the First World that a non-proprietary method of encoding characters was needed. The International Organization for Standardization...
24 KB (1,638 words) - 17:48, 4 March 2025
Code page 951 (category Encodings of Asian languages)
PC Data KS code, the double byte component of their code page 949, an encoding for the Korean language. See Code page 949 (IBM). The code page number...
2 KB (244 words) - 22:31, 23 November 2023
8859 series of ASCII-based standard character encodings, first edition published in 2001. The same encoding was defined as Romanian Standard SR 14111 in...
18 KB (343 words) - 08:45, 9 June 2025
though the introduction of ISO/IEC 8859-9 superseded it for Turkish. The encoding was popular for users of Esperanto, but fell out of use as application...
17 KB (261 words) - 01:54, 26 August 2024
Anne. "9. Legacy single-byte encodings". Encoding Standard. WHATWG. Note: ISO-8859-8 and ISO-8859-8-I are distinct encoding names, because ISO-8859-8 has...
25 KB (785 words) - 01:54, 26 August 2024
Lotus Multi-Byte Character Set (category Character encoding)
Multi-Byte Character Set (LMBCS) is a proprietary multi-byte character encoding originally conceived in 1988 at Lotus Development Corporation with input...
49 KB (1,511 words) - 09:34, 27 May 2025
Xerox Character Code Standard (category Character encoding)
character encoding that was created by Xerox in 1980 for the exchange of information between elements of the Xerox Network Systems Architecture. It encodes the...
238 KB (458 words) - 02:24, 6 February 2025
declare use of ISO-8859-9. However, the WHATWG Encoding Standard, which specifies the character encodings which are permitted in HTML5 and which compliant...
21 KB (587 words) - 13:57, 1 January 2025
Lotus International Character Set (category Character encoding)
International Character Set (LICS) is a proprietary single-byte character encoding introduced in 1985 by Lotus Development Corporation. It is based on the...
34 KB (1,485 words) - 08:50, 27 May 2025
T.51/ISO/IEC 6937 (category Character encoding)
of this standard (plus control codes). But in practice this character encoding is unused on the Internet.[citation needed] The primary set (first half)...
35 KB (1,587 words) - 21:00, 16 July 2025
ISO/IEC 8859-11 (category Encodings of Thai)
is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 2001. It is informally referred to as Latin/Thai...
36 KB (685 words) - 09:05, 1 March 2025
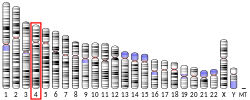
and has a different N-terminus. TMEM128 is neighbored upstream by LYAR, Ly1 antibody reactive, and downstream by OTOP1, Otopetrin 1. TMEM128 Isoform...
25 KB (2,052 words) - 16:40, 19 July 2025