statistics, cluster analysis is the algorithmic grouping of objects into homogeneous groups based on numerical measurements. Model-based clustering based on a...
32 KB (3,525 words) - 20:04, 9 June 2025

(also known as co-clustering or two-mode-clustering), clusters are modeled with both cluster members and relevant attributes. Group models: some algorithms...
75 KB (9,510 words) - 17:19, 16 July 2025
of the modern day. Where model-based clustering characterizes populations using proportions of presupposed ancestral clusters, multidimensional summary...
26 KB (2,799 words) - 16:32, 30 May 2025
information. Mixture models are used for clustering, under the name model-based clustering, and also for density estimation. Mixture models should not be confused...
58 KB (7,855 words) - 11:52, 19 July 2025
and Gaussian mixture modeling. They both use cluster centers to model the data; however, k-means clustering tends to find clusters of comparable spatial...
62 KB (7,767 words) - 01:40, 17 July 2025
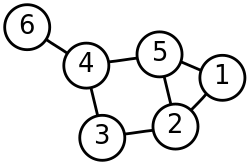
{\displaystyle j} . The general approach to spectral clustering is to use a standard clustering method (there are many such methods, k-means is discussed...
27 KB (3,562 words) - 02:56, 14 May 2025
DBSCAN (redirect from Density Based Spatial Clustering of Applications with Noise)
Density-based spatial clustering of applications with noise (DBSCAN) is a data clustering algorithm proposed by Martin Ester, Hans-Peter Kriegel, Jörg...
29 KB (3,492 words) - 22:56, 19 June 2025
follows: Clustering methods include: hierarchical clustering, k-means, mixture models, model-based clustering, DBSCAN, and OPTICS algorithm Anomaly detection...
31 KB (2,770 words) - 17:17, 16 July 2025
clustering (also referred to as soft clustering or soft k-means) is a form of clustering in which each data point can belong to more than one cluster...
14 KB (2,039 words) - 03:24, 30 June 2025
on clustering and in 1965 he published the paper that invented model-based clustering. He used the mixture of multivariate normal distributions model, estimated...
4 KB (416 words) - 19:07, 9 March 2025
clusters. Strategies for hierarchical clustering generally fall into two categories: Agglomerative: Agglomerative clustering, often referred to as a "bottom-up"...
27 KB (3,067 words) - 05:29, 10 July 2025

model is a random graph generation model that produces graphs with small-world properties, including short average path lengths and high clustering....
11 KB (1,613 words) - 17:30, 19 June 2025
An agent-based model (ABM) is a computational model for simulating the actions and interactions of autonomous agents (both individual or collective entities...
90 KB (9,330 words) - 13:06, 19 June 2025
Feature engineering (section Clustering)
feature engineering has been clustering of feature-objects or sample-objects in a dataset. Especially, feature engineering based on matrix decomposition has...
20 KB (2,184 words) - 08:08, 17 July 2025
Furthermore, Bayesian hierarchical clustering also plays an important role in the development of model-based functional clustering. Functional classification...
48 KB (6,704 words) - 20:31, 18 July 2025

Predictive maintenance (redirect from Condition-based maintenance)
(February 2018). "Fault Class Prediction in Unsupervised Learning using Model-Based Clustering Approach". ResearchGate. doi:10.13140/rg.2.2.22085.14563. Retrieved...
17 KB (2,106 words) - 23:52, 12 June 2025

Learning curve (machine learning) (category Model selection)
David (Summer 2002). "The Learning-Curve Sampling Method Applied to Model-Based Clustering". Journal of Machine Learning Research. 2 (3): 397. Archived from...
6 KB (749 words) - 04:41, 26 May 2025
Classification Clustering Density-Based Clustering Fuzzy C-Means Clustering Hierarchical Clustering Model-based clustering Neighborhood-based Clustering (i.e....
14 KB (1,052 words) - 10:34, 19 June 2025
Document clustering (or text clustering) is the application of cluster analysis to textual documents. It has applications in automatic document organization...
7 KB (886 words) - 02:19, 10 January 2025
Brown clustering is a hard hierarchical agglomerative clustering problem based on distributional information proposed by Peter Brown, William A. Brown...
10 KB (1,198 words) - 01:48, 23 January 2024

countries [as seen by the varying amounts of ancestry inferred by model-based clustering that is representative of a sample from modern Tuscany, Italy (TSI)...
18 KB (2,146 words) - 20:25, 16 May 2025
Non-negative matrix factorization (redirect from Self modeling curve resolution)
equivalent to the minimization of K-means clustering. Furthermore, the computed H {\displaystyle H} gives the cluster membership, i.e., if H k j > H i j {\displaystyle...
68 KB (7,783 words) - 02:31, 2 June 2025

Learning curve (section Models)
David (Summer 2002). "The Learning-Curve Sampling Method Applied to Model-Based Clustering" (PDF). Journal of Machine Learning Research. 2 (3): 397. Gersick...
36 KB (4,349 words) - 09:15, 18 June 2025
issue from the process of actually solving the clustering problem. For a certain class of clustering algorithms (in particular k-means, k-medoids and...
20 KB (2,763 words) - 23:09, 7 January 2025
Hierarchical clustering Single-linkage clustering Conceptual clustering Cluster analysis BIRCH DBSCAN Expectation–maximization (EM) Fuzzy clustering Hierarchical...
39 KB (3,385 words) - 07:36, 7 July 2025
In data mining, cluster-weighted modeling (CWM) is an algorithm-based approach to non-linear prediction of outputs (dependent variables) from inputs (independent...
6 KB (803 words) - 01:07, 23 May 2025

Feature learning (section K-means clustering)
K-means clustering is an approach for vector quantization. In particular, given a set of n vectors, k-means clustering groups them into k clusters (i.e....
45 KB (5,114 words) - 09:22, 4 July 2025

supports various cluster software; for application clustering, there is distcc, and MPICH. Linux Virtual Server, Linux-HA – director-based clusters that allow...
34 KB (3,744 words) - 00:28, 3 May 2025

graph characterized by a high clustering coefficient and low distances. In an example of the social network, high clustering implies the high probability...
38 KB (4,646 words) - 17:51, 18 July 2025
Ensemble learning (redirect from Bayesian model averaging)
Tree models, and Gradient Boosted Tree Models. Models in applications of stacking are generally more task-specific — such as combining clustering techniques...
53 KB (6,692 words) - 01:25, 12 July 2025