of artificial neural networks (ANNs), the neural tangent kernel (NTK) is a kernel that describes the evolution of deep artificial neural networks during...
35 KB (5,146 words) - 10:08, 16 April 2025
Fisher kernel Graph kernels Kernel smoother Polynomial kernel Radial basis function kernel (RBF) String kernels Neural tangent kernel Neural network...
13 KB (1,670 words) - 19:58, 13 February 2025
artificial neural networks after random initialization of their parameters, but before training; it appears as a term in neural tangent kernel prediction...
20 KB (2,964 words) - 01:28, 19 April 2024

Clement Hongler (2018). Neural Tangent Kernel: Convergence and Generalization in Neural Networks (PDF). 32nd Conference on Neural Information Processing...
168 KB (17,637 words) - 20:48, 21 April 2025
architecture and initializations hyper-parameters. The Neural Tangent Kernel describes the evolution of neural network predictions during gradient descent training...
9 KB (869 words) - 11:20, 5 February 2024
Finland. (Known as NTK Nakkila) Neural tangent kernel, a mathematical tool to describe the training of artificial neural networks NTK, a Niterra brand of...
616 bytes (108 words) - 21:37, 30 August 2024
A convolutional neural network (CNN) is a type of feedforward neural network that learns features via filter (or kernel) optimization. This type of deep...
138 KB (15,599 words) - 14:46, 5 May 2025
(Not to be confused with the lazy learning regime, see Neural tangent kernel). In machine learning, lazy learning is a learning method in which generalization...
9 KB (1,102 words) - 00:12, 17 April 2025
')=e^{-\alpha \psi (\theta ,\theta ')},\alpha >0.} The sigmoid kernel, or hyperbolic tangent kernel, is defined as K ( x , y ) = tanh ( γ x T y + r ) , x ...
24 KB (4,346 words) - 08:53, 20 April 2025
Recurrent neural networks (RNNs) are a class of artificial neural networks designed for processing sequential data, such as text, speech, and time series...
89 KB (10,413 words) - 06:01, 17 April 2025

Feedforward refers to recognition-inference architecture of neural networks. Artificial neural network architectures are based on inputs multiplied by weights...
21 KB (2,242 words) - 04:14, 9 January 2025
Gaussian process (redirect from Bayesian Kernel Ridge Regression)
Sohl-Dickstein, Jascha; Schoenholz, Samuel S. (2020). "Neural Tangents: Fast and Easy Infinite Neural Networks in Python". International Conference on Learning...
44 KB (5,929 words) - 11:10, 3 April 2025
Support vector machine (section Kernel trick)
using the kernel trick, representing the data only through a set of pairwise similarity comparisons between the original data points using a kernel function...
65 KB (9,068 words) - 08:13, 28 April 2025

In the context of artificial neural networks, the rectifier or ReLU (rectified linear unit) activation function is an activation function defined as the...
21 KB (2,794 words) - 04:18, 27 April 2025
model Kernel adaptive filter Kernel density estimation Kernel eigenvoice Kernel embedding of distributions Kernel method Kernel perceptron Kernel random...
39 KB (3,386 words) - 22:50, 15 April 2025
Dimensionality reduction (section Kernel PCA)
Anouar, F. (2000). "Generalized Discriminant Analysis Using a Kernel Approach". Neural Computation. 12 (10): 2385–2404. CiteSeerX 10.1.1.412.760. doi:10...
21 KB (2,248 words) - 07:14, 18 April 2025
Weight initialization (category Artificial neural networks)
initialized. Similarly, trainable parameters in convolutional neural networks (CNNs) are called kernels and biases, and this article also describes these. We...
24 KB (2,863 words) - 19:13, 7 April 2025

Müller, K.-R. (1998). "Nonlinear Component Analysis as a Kernel Eigenvalue Problem". Neural Computation. 10 (5). MIT Press: 1299–1319. doi:10.1162/089976698300017467...
48 KB (6,112 words) - 15:28, 18 April 2025
Multilayer perceptron (category Neural network architectures)
learning, a multilayer perceptron (MLP) is a name for a modern feedforward neural network consisting of fully connected neurons with nonlinear activation...
16 KB (1,932 words) - 07:03, 29 December 2024
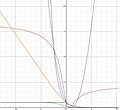
The Tangent loss is quasi-convex and is bounded for large negative values which makes it less sensitive to outliers. Interestingly, the Tangent loss...
24 KB (4,212 words) - 19:04, 6 December 2024
Gated recurrent unit (redirect from GRU neural net)
Gated recurrent units (GRUs) are a gating mechanism in recurrent neural networks, introduced in 2014 by Kyunghyun Cho et al. The GRU is like a long short-term...
8 KB (1,278 words) - 22:37, 2 January 2025

Long short-term memory (category Neural network architectures)
Long short-term memory (LSTM) is a type of recurrent neural network (RNN) aimed at mitigating the vanishing gradient problem commonly encountered by traditional...
52 KB (5,788 words) - 14:41, 3 May 2025

Activation function (category Artificial neural networks)
kernels of the previous neural network layer while i {\displaystyle i} iterates through the number of kernels of the current layer. In quantum neural...
25 KB (1,960 words) - 05:35, 26 April 2025
Vanishing gradient problem (category Artificial neural networks)
and later layers encountered when training neural networks with backpropagation. In such methods, neural network weights are updated proportional to...
24 KB (3,706 words) - 18:44, 7 April 2025
dynamic reposing and tangent distance for drug activity prediction Archived 7 December 2019 at the Wayback Machine." Advances in Neural Information Processing...
263 KB (14,635 words) - 19:56, 1 May 2025
subalgebra of kernels which can be solved in O ( n ) {\displaystyle O(n)} . neural-tangents is a specialized package for infinitely wide neural networks....
28 KB (1,681 words) - 23:28, 18 March 2025
Wasserstein GAN (category Neural network architectures)
1 {\displaystyle \sup _{x}|h'(x)|\leq 1} . For example, the hyperbolic tangent function h = tanh {\displaystyle h=\tanh } satisfies the requirement. Then...
16 KB (2,884 words) - 07:23, 26 January 2025

v , w {\displaystyle v,w} on M {\displaystyle M} (i.e. sections of the tangent bundle T M {\displaystyle \mathrm {T} M} ), g ( v , w ) = g ′ ( f ∗ v ...
18 KB (2,425 words) - 20:31, 9 April 2025
G_{x}\ ,} where d G {\displaystyle \ \operatorname {d} G} denotes the tangent map or Jacobian T M → T R p {\displaystyle \ TM\to T\mathbb {R} ^{p}~}...
52 KB (7,988 words) - 17:30, 30 April 2025
Diffeomorphometry (category Neural engineering)
metric ‖ ⋅ ‖ φ {\displaystyle \|\cdot \|_{\varphi }} associated to the tangent spaces at all φ ∈ Diff V {\displaystyle \varphi \in \operatorname {Diff}...
24 KB (3,609 words) - 16:21, 8 April 2025