
Character encoding is a convention of using a numeric value to represent each character of a writing script. Not only can a character set include natural...
31 KB (3,793 words) - 16:38, 7 July 2025
URL encoding, officially known as percent-encoding, is a method to encode arbitrary data in a uniform resource identifier (URI) using only the US-ASCII...
18 KB (1,684 words) - 20:02, 17 July 2025
character encoding via XML declaration, as follows: <?xml version="1.0" encoding="utf-8"?> With this second approach, because the character encoding cannot...
24 KB (2,454 words) - 05:06, 16 November 2024
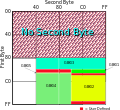
2312-80 in its usual encoding, GBK/1 being the non-hanzi region and GBK/2 the hanzi region. GB 2312, or more properly the EUC-CN encoding thereof, takes a...
14 KB (1,480 words) - 20:07, 15 July 2025
published in 1980. Two encoding schemes existed for GB 2312: a one-or-two byte 8-bit EUC-CN encoding commonly used, and a 7-bit encoding called HZ for usenet...
8 KB (955 words) - 20:13, 13 July 2025
variants of BCD encode the characters '0' through '9' as the corresponding binary values. Technically, binary-coded decimal describes the encoding of decimal...
25 KB (1,945 words) - 22:55, 17 July 2025

left-to-right scripts when discussing encoding issues. Libraries cooperated on encoding standards for JACKPHY characters in the early 1980s. According to Ken...
8 KB (913 words) - 21:21, 8 July 2025
Base64 (redirect from Base64 (encoding scheme))
binary-to-text encoding schemes that transforms binary data into a sequence of printable characters, limited to a set of 64 unique characters. More specifically...
39 KB (3,740 words) - 19:08, 9 July 2025
encoding is encoding of data in plain text. More precisely, it is an encoding of binary data in a sequence of printable characters. These encodings are...
22 KB (1,374 words) - 13:35, 9 March 2025
26 characters from А (0xE1) in KOI8-R are А, Б, Ц, Д, Е, Ф, Г, Х, И, Й, К, Л, М, Н, О, П, Я, Р, С, Т, У, Ж, В, Ь, Ы, З. The original KOI encoding (1967)...
14 KB (1,228 words) - 12:34, 21 June 2025

Plain text (section Character encodings)
correctly interpreted via the character encoding in effect. For example, a file or string consisting of "hello" (in any encoding), following by 4 bytes that...
12 KB (1,653 words) - 11:42, 5 June 2025
The HZ character encoding is an encoding of GB 2312 that was formerly commonly used in email and USENET postings. It was designed in 1989 by Fung Fung...
6 KB (553 words) - 05:31, 1 March 2024
UTF-8 (redirect from UTF-8 encoding)
UTF-8 is a character encoding standard used for electronic communication. Defined by the Unicode Standard, the name is derived from Unicode Transformation...
49 KB (5,077 words) - 04:15, 21 July 2025
or Six-Bit Transmission Code, was, for a few years, one of the three character sets used by IBM for Binary Synchronous Communications. Transmission using...
12 KB (199 words) - 15:58, 31 March 2025
Mac OS Roman (redirect from Mac-Roman encoding)
Mac OS Roman is a character encoding created by Apple Computer, Inc. for use by Macintosh computers. It is suitable for representing text in English and...
22 KB (366 words) - 22:42, 26 January 2025
Unicode and HTML (section Character encoding)
the document's characters are encoded as a sequence of bit octets (bytes) according to a particular character encoding. This encoding may either be a...
22 KB (2,590 words) - 21:13, 10 October 2024

Newline (redirect from New line character)
control character or sequence of control characters in character encoding specifications such as ASCII, EBCDIC, Unicode, etc. This character, or a sequence...
39 KB (4,387 words) - 10:59, 15 July 2025

GB 18030 (redirect from GB18030 character encoding)
(character encoding) § Encoding. Some code points are encoded with two bytes (upper row), the others with four bytes (lower row). U+FFFF is encoded as...
44 KB (3,218 words) - 00:46, 18 July 2025

Mojibake (redirect from Broken character)
one encoding, when the same binary code constitutes one symbol in the other encoding. This is either because of differing constant length encoding (as...
60 KB (5,936 words) - 11:37, 1 July 2025
In computing, JIS encoding refers to several Japanese Industrial Standards for encoding the Japanese language. Strictly speaking, the term means either:...
3 KB (905 words) - 13:24, 2 December 2023

Japanese language and computers (redirect from Japanese character encoding)
supports the required character. Unicode was intended to solve all encoding problems over all languages. The UTF-8 encoding used to encode Unicode in web pages...
14 KB (1,742 words) - 02:31, 10 January 2025
A variable-width encoding is a type of character encoding scheme in which codes of differing lengths are used to encode a character set (a repertoire of...
10 KB (1,556 words) - 21:26, 14 February 2025
Byte order mark (section Byte-order marks by encoding)
and 32-bit encodings; the fact that the text stream's encoding is Unicode, to a high level of confidence; which Unicode character encoding is used. BOM...
15 KB (1,910 words) - 21:50, 27 June 2025
[clarification needed] Another encoding, UTF-32 (previously named UCS-4), uses four bytes (total 32 bits) to encode a single character of the codespace. UTF-32...
14 KB (1,916 words) - 18:45, 15 June 2025
A double-byte character set (DBCS) is a character encoding in which either all characters (including control characters) are encoded in two bytes, or merely...
5 KB (628 words) - 10:48, 23 June 2025
JSON (section Character encoding)
constrain the character encoding of the Unicode characters in a JSON text, the vast majority of implementations assume UTF-8 encoding; for interoperability...
46 KB (4,867 words) - 19:17, 20 July 2025
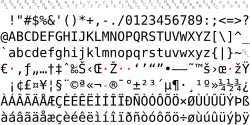
Windows-1252 (section Related encodings)
Windows-1252 or CP-1252 (Windows code page 1252) is a legacy single-byte character encoding that is used by default (as the "ANSI code page") in Microsoft Windows...
40 KB (1,594 words) - 15:02, 9 July 2025
multi-byte character encoding used in the TRON project. It is similar to Unicode but does not use Unicode's Han unification process: each character from each...
8 KB (828 words) - 21:43, 18 July 2025
Code point (category Character encoding)
commonly used in character encoding, where a code point is a numerical value that maps to a specific character. In character encoding code points usually...
7 KB (908 words) - 02:59, 2 May 2025