Clustering high-dimensional data is the cluster analysis of data with anywhere from a few dozen to many thousands of dimensions. Such high-dimensional...
18 KB (2,284 words) - 20:48, 27 October 2024
Dimensionality reduction, or dimension reduction, is the transformation of data from a high-dimensional space into a low-dimensional space so that the...
21 KB (2,248 words) - 07:14, 18 April 2025
Clustering is the problem of partitioning data points into groups based on their similarity. Correlation clustering provides a method for clustering a...
14 KB (2,006 words) - 02:12, 5 May 2025
The curse of dimensionality refers to various phenomena that arise when analyzing and organizing data in high-dimensional spaces that do not occur in low-dimensional...
32 KB (4,182 words) - 17:46, 16 April 2025

to Cluster analysis. Automatic clustering algorithms Balanced clustering Clustering high-dimensional data Conceptual clustering Consensus clustering Constrained...
75 KB (9,513 words) - 02:05, 30 April 2025
mixture modeling. They both use cluster centers to model the data; however, k-means clustering tends to find clusters of comparable spatial extent, while...
62 KB (7,754 words) - 11:44, 13 March 2025
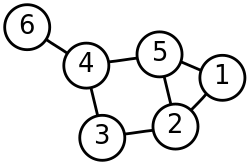
between data points with indices i {\displaystyle i} and j {\displaystyle j} . The general approach to spectral clustering is to use a standard clustering method...
27 KB (3,562 words) - 23:50, 24 April 2025
well matched to its own cluster and poorly matched to neighboring clusters. If most objects have a high value, then the clustering configuration is appropriate...
14 KB (2,216 words) - 07:52, 17 April 2025
SUBCLU (category Cluster analysis algorithms)
an algorithm for clustering high-dimensional data by Karin Kailing, Hans-Peter Kriegel and Peer Kröger. It is a subspace clustering algorithm that builds...
6 KB (1,388 words) - 22:15, 7 December 2022
hierarchy of clusters. Strategies for hierarchical clustering generally fall into two categories: Agglomerative: Agglomerative clustering, often referred...
33 KB (3,889 words) - 02:22, 7 May 2025
In computer science, data stream clustering refers to the process of grouping data points that arrive in a continuous, rapid, and potentially unbounded...
15 KB (2,047 words) - 01:14, 24 April 2025
Biclustering (redirect from Two-mode clustering)
Biclustering, block clustering, Co-clustering or two-mode clustering is a data mining technique which allows simultaneous clustering of the rows and columns...
26 KB (3,159 words) - 13:32, 27 February 2025
In statistical theory, the field of high-dimensional statistics studies data whose dimension is larger (relative to the number of datapoints) than typically...
20 KB (2,559 words) - 15:42, 4 October 2024

T-distributed stochastic neighbor embedding (category Dimension reduction)
statistical method for visualizing high-dimensional data by giving each datapoint a location in a two or three-dimensional map. It is based on Stochastic...
15 KB (2,065 words) - 03:13, 22 April 2025
Outline of machine learning (category Data mining)
selection algorithm Cluster-weighted modeling Clustering high-dimensional data Clustering illusion CoBoosting Cobweb (clustering) Cognitive computer Cognitive...
39 KB (3,386 words) - 22:50, 15 April 2025
probability, etc. Intrinsically, functional data are infinite dimensional. The high intrinsic dimensionality of these data brings challenges for theory as well...
48 KB (6,704 words) - 18:08, 26 March 2025
issue from the process of actually solving the clustering problem. For a certain class of clustering algorithms (in particular k-means, k-medoids and...
20 KB (2,763 words) - 23:09, 7 January 2025

Self-organizing map (category Dimension reduction)
low-dimensional (typically two-dimensional) representation of a higher-dimensional data set while preserving the topological structure of the data. For...
34 KB (4,063 words) - 21:25, 10 April 2025
BIRCH (redirect from Birch (data clustering))
incrementally and dynamically cluster incoming, multi-dimensional metric data points in an attempt to produce the best quality clustering for a given set of resources...
13 KB (2,275 words) - 14:43, 28 April 2025
useful for clustering. Different Gaussian model-based clustering methods have been developed with an eye to handling high-dimensional data. These include...
32 KB (3,522 words) - 22:43, 26 January 2025
K-means algorithm or the hierarchical clustering algorithm. It is intended to speed up clustering operations on large data sets, where using another algorithm...
3 KB (398 words) - 16:27, 6 September 2024
CURE algorithm (redirect from Cure data clustering)
(Clustering Using REpresentatives) is an efficient data clustering algorithm for large databases[citation needed]. Compared with K-means clustering it...
6 KB (788 words) - 18:03, 29 March 2025
Medoid (category Cluster analysis)
2022). "K Means Clustering on High Dimensional Data". Medium. "What are the main drawbacks of using k-means for high-dimensional data?".[self-published...
33 KB (4,003 words) - 00:45, 15 December 2024
diagram Rate-distortion function Data clustering Centroidal Voronoi tessellation Image segmentation K-means clustering Autoencoder Deep Learning Part of...
13 KB (1,649 words) - 10:50, 3 February 2024
procedure Cluster analysis Cluster randomised controlled trial Cluster sampling Cluster-weighted modeling Clustering high-dimensional data CMA-ES (Covariance...
87 KB (8,280 words) - 23:04, 12 March 2025
Consensus clustering is a method of aggregating (potentially conflicting) results from multiple clustering algorithms. Also called cluster ensembles or...
22 KB (2,951 words) - 05:21, 11 March 2025
Random mapping (category Data analysis)
result in a reduced vector. When the data vectors are high-dimensional it is computationally infeasible to use data analysis or pattern recognition algorithms...
2 KB (195 words) - 02:16, 29 April 2024
Locality-sensitive hashing (category Dimension reduction)
as a way to reduce the dimensionality of high-dimensional data; high-dimensional input items can be reduced to low-dimensional versions while preserving...
30 KB (4,024 words) - 17:28, 16 April 2025
DBSCAN (redirect from Density Based Spatial Clustering of Applications with Noise)
Density-based spatial clustering of applications with noise (DBSCAN) is a data clustering algorithm proposed by Martin Ester, Hans-Peter Kriegel, Jörg...
29 KB (3,492 words) - 20:41, 25 January 2025

Nonlinear dimensionality reduction, also known as manifold learning, is any of various related techniques that aim to project high-dimensional data, potentially...
48 KB (6,112 words) - 15:28, 18 April 2025