the Hodges–Lehmann estimator is a consistent and median-unbiased estimate of the population median. For non-symmetric populations, the Hodges–Lehmann estimator...
9 KB (1,077 words) - 13:24, 2 June 2025

Median (redirect from Median unbiased estimator)
the Hodges–Lehmann estimator is a robust and highly efficient estimator of the population median; for non-symmetric distributions, the Hodges–Lehmann estimator...
63 KB (7,987 words) - 23:47, 14 June 2025

one of the eponyms of the Lehmann–Scheffé theorem and of the Hodges–Lehmann estimator of the median of a population. Lehmann was born in Strasbourg, Alsace-Lorraine...
8 KB (705 words) - 03:20, 20 June 2025
the Lehmann–Scheffé theorem ties together completeness, sufficiency, uniqueness, and best unbiased estimation. The theorem states that any estimator that...
6 KB (993 words) - 10:06, 20 June 2025
rest of his career. Hodges is best known for his contributions to the field of statistics, including the Hodges–Lehmann estimator, the nearest neighbor...
3 KB (203 words) - 02:55, 15 June 2023
Resampling (statistics) (redirect from Jackknife estimator)
delete-1, such as the delete-m jackknife or the delete-all-but-2 Hodges–Lehmann estimator, overcome this problem for the medians and quantiles by relaxing...
18 KB (2,236 words) - 09:36, 16 March 2025
minimum-variance unbiased estimator (MVUE) or uniformly minimum-variance unbiased estimator (UMVUE) is an unbiased estimator that has lower variance than...
7 KB (1,109 words) - 21:36, 14 April 2025
Efficiency (statistics) (redirect from Efficient estimator)
of quality of an estimator, of an experimental design, or of a hypothesis testing procedure. Essentially, a more efficient estimator needs fewer input...
22 KB (3,066 words) - 01:10, 20 March 2025
In statistics, the bias of an estimator (or bias function) is the difference between this estimator's expected value and the true value of the parameter...
34 KB (5,367 words) - 15:44, 15 April 2025
Rao–Blackwell theorem (redirect from Rao-Blackwell estimator)
that characterizes the transformation of an arbitrarily crude estimator into an estimator that is optimal by the mean-squared-error criterion or any of...
13 KB (2,174 words) - 20:32, 19 June 2025
Completeness (statistics) (redirect from Unbiased estimator of zero)
X_{2})} is sufficient but not complete. It admits a non-zero unbiased estimator of zero, namely X 1 − X 2 {\textstyle X_{1}-X_{2}} . Most parametric models...
10 KB (1,548 words) - 16:15, 10 January 2025

The Kaplan–Meier estimator, also known as the product limit estimator, is a non-parametric statistic used to estimate the survival function from lifetime...
27 KB (4,444 words) - 23:08, 19 June 2025
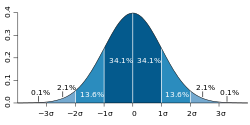
Standard error (section Accuracy of the estimator)
The standard error (SE) of a statistic (usually an estimator of a parameter, like the average or mean) is the standard deviation of its sampling distribution...
20 KB (2,781 words) - 01:28, 24 June 2025
In statistics, M-estimators are a broad class of extremum estimators for which the objective function is a sample average. Both non-linear least squares...
22 KB (2,854 words) - 17:15, 5 November 2024
Gauss–Markov theorem does not apply. Similar to the Hodges' estimator, the James-Stein estimator is superefficient and non-regular at θ = 0 {\displaystyle...
16 KB (2,147 words) - 18:26, 13 June 2025
standard deviation. Such a statistic is called an estimator, and the estimator (or the value of the estimator, namely the estimate) is called a sample standard...
59 KB (8,235 words) - 23:08, 17 June 2025
The Nelson–Aalen estimator is a non-parametric estimator of the cumulative hazard rate function in case of censored data or incomplete data. It is used...
4 KB (417 words) - 18:41, 25 May 2025

unbiased estimator (dividing by a number larger than n − 1) and is a simple example of a shrinkage estimator: one "shrinks" the unbiased estimator towards...
61 KB (10,215 words) - 16:29, 24 May 2025
Maximum a posteriori estimation (redirect from MAP estimator)
estimator approaches the MAP estimator, provided that the distribution of θ {\displaystyle \theta } is quasi-concave. But generally a MAP estimator is...
11 KB (1,725 words) - 05:26, 19 December 2024
have a random sample of n people. The sample mean could serve as a good estimator of the population mean. Then we have: The difference between the height...
16 KB (2,164 words) - 16:12, 23 May 2025

deviation ellipse is lower. The derivation of the maximum-likelihood estimator of the covariance matrix of a multivariate normal distribution is straightforward...
65 KB (9,594 words) - 15:19, 3 May 2025
Maximum likelihood estimation (redirect from Maximum likelihood estimator)
can be solved analytically; for instance, the ordinary least squares estimator for a linear regression model maximizes the likelihood when the random...
68 KB (9,706 words) - 19:59, 16 June 2025
sufficient and ancillary statistics Lehmann–Scheffé theorem: a complete sufficient estimator is the best estimator of its expectation Rao–Blackwell theorem...
35 KB (6,712 words) - 17:16, 23 June 2025
treatments) was quantified using the Hodges–Lehmann (HL) estimator, which is consistent with the Wilcoxon test. This estimator (HLΔ) is the median of all possible...
44 KB (5,746 words) - 16:47, 7 June 2025
The ratio estimator is a statistical estimator for the ratio of means of two random variables. Ratio estimates are biased and corrections must be made...
22 KB (4,015 words) - 19:09, 2 May 2025
{s}{\bar {x}}}} But this estimator, when applied to a small or moderately sized sample, tends to be too low: it is a biased estimator. For normally distributed...
30 KB (4,017 words) - 13:36, 17 April 2025
maximum likelihood estimator (MLE) of the covariance matrix differs from the ordinary least squares (OLS) estimator. MLE estimator:[citation needed] Σ...
22 KB (3,542 words) - 14:02, 25 May 2025
In estimation theory and decision theory, a Bayes estimator or a Bayes action is an estimator or decision rule that minimizes the posterior expected value...
22 KB (3,845 words) - 16:15, 22 August 2024

the bootstrap. Given a sample of size n {\displaystyle n} , a jackknife estimator can be built by aggregating the parameter estimates from each subsample...
13 KB (2,087 words) - 18:25, 29 May 2025
uncorrelated). Let α ^ , β ^ = least-squares estimators , S E α ^ , S E β ^ = the standard errors of least-squares estimators . {\displaystyle {\begin{aligned}{\hat...
52 KB (7,010 words) - 16:42, 18 June 2025