Two-step M-estimators deals with M-estimation problems that require preliminary estimation to obtain the parameter of interest. Two-step M-estimation is...
7 KB (1,250 words) - 21:30, 24 February 2025
In statistics, M-estimators are a broad class of extremum estimators for which the objective function is a sample average. Both non-linear least squares...
22 KB (2,854 words) - 17:15, 5 November 2024
Generated regressor (category M-estimators)
two-step M-estimator and thus consistency and asymptotic normality of the estimator can be verified using the general theory of two-step M-estimator....
4 KB (663 words) - 20:30, 12 January 2025
Heckman correction (redirect from Heckman two-step estimation)
generalized, by Heckman and by others. The Heckman correction is a two-step M-estimator where the covariance matrix generated by OLS estimation of the second...
14 KB (1,569 words) - 10:40, 25 May 2025
Maximum likelihood estimation (redirect from Maximum likelihood estimator)
can be solved analytically; for instance, the ordinary least squares estimator for a linear regression model maximizes the likelihood when the random...
68 KB (9,706 words) - 19:59, 16 June 2025

Spearman's rank correlation coefficient estimator, to give a sequential Spearman's correlation estimator. This estimator is phrased in terms of linear algebra...
33 KB (4,320 words) - 00:47, 18 June 2025
Generalized method of moments (redirect from GMM estimator)
method demonstrated a better performance than the traditional two-step GMM: the estimator has smaller median bias (although fatter tails), and the J-test...
24 KB (3,351 words) - 21:10, 14 April 2025
The ratio estimator is a statistical estimator for the ratio of means of two random variables. Ratio estimates are biased and corrections must be made...
22 KB (4,015 words) - 19:09, 2 May 2025
{\displaystyle X} has two defining parameters, its mean μ {\displaystyle \mu } and variance σ 2 {\displaystyle \sigma ^{2}} . A variance estimator: s 2 = ∑ i =...
10 KB (1,220 words) - 00:28, 20 June 2025
Variance inflation factor (section Step two)
is the root mean squared error (RMSE) (note that RMSE2 is a consistent estimator of the true variance of the error term, σ 2 {\displaystyle \sigma ^{2}}...
12 KB (1,770 words) - 00:42, 2 May 2025
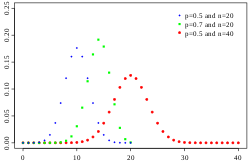
25% midsummary; it is an L-estimator. MH ( X ) = Q 1 , 3 ( X ) ¯ = Q 1 ( X ) + Q 3 ( X ) 2 = P 25 ( X ) + P 75 ( X ) 2 = M 25 ( X ) {\displaystyle \operatorname...
251 KB (31,179 words) - 19:07, 15 June 2025
Minimum mean square error (redirect from MMSE estimator)
square error (MMSE) estimator is an estimation method which minimizes the mean square error (MSE), which is a common measure of estimator quality, of the...
41 KB (9,310 words) - 08:40, 13 May 2025

Cluster sampling (section Two-stage cluster sampling)
the estimators, but cost savings may make such an increase in sample size feasible. For the organization of a population census, the first step is usually...
16 KB (2,332 words) - 04:09, 13 December 2024
{p}}={\frac {x}{n}}.} This estimator is found using maximum likelihood estimator and also the method of moments. This estimator is unbiased and uniformly...
53 KB (7,554 words) - 03:55, 26 May 2025
In target tracking, the multi-fractional order estimator (MFOE) is an alternative to the Kalman filter. The MFOE is focused strictly on simple and pragmatic...
33 KB (5,698 words) - 20:47, 27 May 2025
Innovation method (section Innovation estimator)
parameters. The innovation estimator can be classified as a M-estimator, a quasi-maximum likelihood estimator or a prediction error estimator depending on the inferential...
39 KB (6,480 words) - 20:27, 22 May 2025
Bootstrapping is a procedure for estimating the distribution of an estimator by resampling (often with replacement) one's data or a model estimated from...
69 KB (9,407 words) - 17:54, 23 May 2025
Horvitz–Thompson estimator, also called the π {\displaystyle \pi } -estimator. This estimator can be itself estimated using the pwr-estimator (i.e.: p {\displaystyle...
44 KB (9,001 words) - 09:30, 21 May 2025

\quad } therefore r is a biased estimator of ρ . {\displaystyle \rho .} The unique minimum variance unbiased estimator radj is given by where: r , n {\displaystyle...
58 KB (8,398 words) - 00:35, 24 June 2025
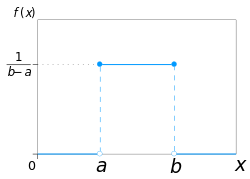
unbiased estimator (UMVUE) for the maximum is: b ^ UMVU = k + 1 k m = m + m k , {\displaystyle {\hat {b}}_{\text{UMVU}}={\frac {k+1}{k}}m=m+{\frac {m}{k}}...
28 KB (4,230 words) - 23:30, 5 April 2025

statistical criterion, which is related to the variance-matrix of the estimator. Specifying an appropriate model and specifying a suitable criterion function...
44 KB (4,412 words) - 10:22, 24 June 2025
matrix. The sample covariance matrix (SCM) is an unbiased and efficient estimator of the covariance matrix if the space of covariance matrices is viewed...
26 KB (4,026 words) - 14:17, 16 May 2025

asymptotic properties of the two definitions that are given above are the same. By the strong law of large numbers, the estimator F ^ n ( t ) {\displaystyle...
13 KB (1,514 words) - 14:05, 27 February 2025
Principal component regression (section Fundamental characteristics and applications of the PCR estimator)
making PCR a kind of regularized procedure and also a type of shrinkage estimator. Often the principal components with higher variances (the ones based...
34 KB (5,109 words) - 04:50, 9 November 2024

distribution. Gauss used M, M′, M′′, ... to denote the measurements of some unknown quantity V, and sought the most probable estimator of that quantity: the...
148 KB (21,558 words) - 12:27, 26 June 2025
Several estimators belong to this class: κ=0: OLS κ=1: 2SLS. Note indeed that in this case, I − κ M = I − M = P {\displaystyle I-\kappa M=I-M=P} the usual...
26 KB (3,353 words) - 16:51, 2 January 2025
correlation integral is used to estimate the correlation dimension. An estimator of the correlation integral is the correlation sum: C ( ε ) = 1 N 2 ∑...
2 KB (300 words) - 02:47, 24 October 2024
parameter value under the null hypothesis. Intuitively, if the restricted estimator is near the maximum of the likelihood function, the score should not differ...
11 KB (1,600 words) - 03:50, 20 June 2025
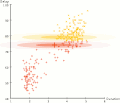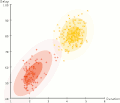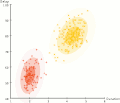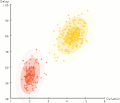
Expectation–maximization algorithm (section M step)
parameters, and a maximization (M) step, which computes parameters maximizing the expected log-likelihood found on the E step. These parameter-estimates are...
50 KB (7,512 words) - 16:40, 23 June 2025
_{n}).} Here H ( θ , X ) {\displaystyle H(\theta ,X)} is an unbiased estimator of ∇ g ( θ ) {\displaystyle \nabla g(\theta )} . If X {\displaystyle X}...
28 KB (4,388 words) - 08:32, 27 January 2025