In Bayesian statistics, a hyperparameter is a parameter of a prior distribution; the term is used to distinguish them from parameters of the model for...
4 KB (493 words) - 04:17, 5 October 2024
Hyperparameter may refer to: Hyperparameter (machine learning) Hyperparameter (Bayesian statistics) This disambiguation page lists articles associated...
130 bytes (41 words) - 04:17, 5 October 2024
in the 21st century, Bayesian optimizations have found prominent use in machine learning problems for optimizing hyperparameter values. The term is generally...
21 KB (2,323 words) - 14:01, 8 June 2025
Fundamentally, Bayesian inference uses a prior distribution to estimate posterior probabilities. Bayesian inference is an important technique in statistics, and...
68 KB (8,957 words) - 00:16, 2 June 2025
Prior probability (redirect from Bayesian prior)
model or a latent variable rather than an observable variable. In Bayesian statistics, Bayes' rule prescribes how to update the prior with new information...
43 KB (6,753 words) - 20:06, 15 April 2025
Empirical Bayes method (redirect from Empirical Bayesian)
(likewise for estimates of the variance). Bayes estimator Bayesian network Hyperparameter Hyperprior Best linear unbiased prediction Robbins lemma Spike-and-slab...
17 KB (2,658 words) - 22:05, 6 June 2025
secant distribution Hypergeometric distribution Hyperparameter (Bayesian statistics) Hyperparameter (machine learning) Hyperprior Hypoexponential distribution...
87 KB (8,280 words) - 23:04, 12 March 2025
Variational Bayesian methods are a family of techniques for approximating intractable integrals arising in Bayesian inference and machine learning. They...
56 KB (11,235 words) - 18:32, 21 January 2025
Conjugate prior (category Bayesian statistics)
In Bayesian probability theory, if, given a likelihood function p ( x ∣ θ ) {\displaystyle p(x\mid \theta )} , the posterior distribution p ( θ ∣ x ) {\displaystyle...
33 KB (2,246 words) - 18:05, 28 April 2025
Gaussian process (redirect from Bayesian Kernel Ridge Regression)
the development of multiple approximation methods. Bayes linear statistics Bayesian interpretation of regularization Kriging Gaussian free field Gauss–Markov...
44 KB (5,929 words) - 11:10, 3 April 2025
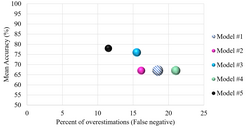
for many different hyperparameters (or even different model types) and the validation set is used to determine the best hyperparameter set (and model type)...
44 KB (5,781 words) - 09:14, 19 February 2025
estimate. Frequentist statistics may yield conclusions seemingly incompatible with those offered by Bayesian statistics due to the Bayesian treatment of the...
21 KB (3,603 words) - 14:51, 16 April 2025
Posterior predictive distribution (redirect from Bayesian predictive density)
In Bayesian statistics, the posterior predictive distribution is the distribution of possible unobserved values conditional on the observed values. Given...
16 KB (2,510 words) - 17:47, 24 February 2024

kernel hyperparameters using, for example, maximum likelihood estimation. The estimation of kernel hyperparameters introduces adaptivity into Bayesian quadrature...
19 KB (2,589 words) - 04:43, 14 June 2025
1 … N , F ( x | θ ) = as above α = shared hyperparameter for component parameters β = shared hyperparameter for mixture weights H ( θ | α ) = prior probability...
57 KB (7,792 words) - 03:39, 19 April 2025

Dirichlet distribution (section Bayesian models)
Dirichlet distributions are commonly used as prior distributions in Bayesian statistics, and in fact, the Dirichlet distribution is the conjugate prior of...
48 KB (7,588 words) - 15:09, 7 June 2025

optimizing decision trees for better performance, solving sudoku puzzles, hyperparameter optimization, and causal inference. In a genetic algorithm, a population...
69 KB (8,221 words) - 21:33, 24 May 2025
Uncertainty quantification (section Bayesian)
all the fixed hyperparameters in previous modules. Module 4: Prediction of the experimental response and discrepancy function Fully Bayesian approach requires...
29 KB (3,910 words) - 22:15, 9 June 2025
Model selection (redirect from Information criterion (statistics))
algorithmic approaches to model selection include feature selection, hyperparameter optimization, and statistical learning theory. In its most basic forms...
21 KB (2,412 words) - 01:50, 1 May 2025
Machine learning (section Bayesian networks)
Gaussian processes are popular surrogate models in Bayesian optimisation used to do hyperparameter optimisation. A genetic algorithm (GA) is a search...
140 KB (15,573 words) - 11:13, 9 June 2025

Neural network (machine learning) (redirect from Bayesian neural network)
separable pattern classes. Subsequent developments in hardware and hyperparameter tunings have made end-to-end stochastic gradient descent the currently...
169 KB (17,641 words) - 00:21, 11 June 2025

Exponential distribution (section Bayesian inference)
Reineke, David M. (2001). "A Bayesian Look at Classical Estimation: The Exponential Distribution". Journal of Statistics Education. 9 (1). doi:10.1080/10691898...
43 KB (6,647 words) - 17:34, 15 April 2025

Normal distribution (redirect from Normality (statistics))
ISBN 978-0-471-49464-5. O'Hagan, A. (1994) Kendall's Advanced Theory of statistics, Vol 2B, Bayesian Inference, Edward Arnold. ISBN 0-340-52922-9 (Section 5.40) Bryc...
151 KB (22,720 words) - 14:33, 14 June 2025
Neural network Gaussian process (category Bayesian statistics)
it is used in deep information propagation to characterize whether hyperparameters and architectures will be trainable. It is related to other large width...
20 KB (2,964 words) - 01:28, 19 April 2024
Hyperprior (category Bayesian statistics)
In Bayesian statistics, a hyperprior is a prior distribution on a hyperparameter, that is, on a parameter of a prior distribution. As with the term hyperparameter...
5 KB (678 words) - 10:49, 5 October 2024
coefficients generated from a single hyper-hyperparameter. Multilevel models are a subclass of hierarchical Bayesian models, which are general models with...
33 KB (4,923 words) - 17:38, 21 May 2025
Integrated nested Laplace approximations (category Bayesian inference)
{\boldsymbol {x}}} . The hyperparameters of the model are denoted by θ {\displaystyle {\boldsymbol {\theta }}} . As per Bayesian statistics, x {\displaystyle...
13 KB (1,949 words) - 15:44, 6 November 2024

Kriging (section Bayesian kriging)
also possible in a Bayesian approach. Bayesian kriging departs from the optimization of unknown coefficients and hyperparameters, which is understood...
39 KB (6,063 words) - 23:47, 20 May 2025
Support vector machine (section Bayesian SVM)
view allows the application of Bayesian techniques to SVMs, such as flexible feature modeling, automatic hyperparameter tuning, and predictive uncertainty...
65 KB (9,071 words) - 06:34, 24 May 2025
Bernoulli distributed with parameter p i . {\displaystyle p_{i}.} In Bayesian statistics, the Dirichlet distribution is the conjugate prior distribution of...
25 KB (4,008 words) - 04:13, 25 June 2024