In information theory, the cross-entropy between two probability distributions p {\displaystyle p} and q {\displaystyle q} , over the same underlying...
19 KB (3,264 words) - 23:00, 21 April 2025
Kullback–Leibler divergence (redirect from Kullback–Leibler entropy)
statistics, the Kullback–Leibler (KL) divergence (also called relative entropy and I-divergence), denoted D KL ( P ∥ Q ) {\displaystyle D_{\text{KL}}(P\parallel...
77 KB (13,054 words) - 16:34, 16 May 2025
Cross-entropy benchmarking (also referred to as XEB) is a quantum benchmarking protocol which can be used to demonstrate quantum supremacy. In XEB, a...
4 KB (548 words) - 18:33, 10 December 2024

In information theory, the entropy of a random variable quantifies the average level of uncertainty or information associated with the variable's potential...
72 KB (10,264 words) - 06:07, 14 May 2025

binary cross-entropy compares the observed y ∈ { 0 , 1 } {\displaystyle y\in \{0,1\}} with the predicted probabilities. The average binary cross-entropy for...
41 KB (7,041 words) - 15:11, 5 May 2025
The cross-entropy (CE) method is a Monte Carlo method for importance sampling and optimization. It is applicable to both combinatorial and continuous...
7 KB (1,085 words) - 19:50, 23 April 2025
Ensemble learning (section Amended Cross-Entropy Cost: An Approach for Encouraging Diversity in Classification Ensemble)
correlation for regression tasks or using information measures such as cross entropy for classification tasks. Theoretically, one can justify the diversity...
53 KB (6,685 words) - 11:44, 14 May 2025
In physics, the Tsallis entropy is a generalization of the standard Boltzmann–Gibbs entropy. It is proportional to the expectation of the q-logarithm...
22 KB (2,563 words) - 08:13, 27 April 2025
entropy states that the probability distribution which best represents the current state of knowledge about a system is the one with largest entropy,...
31 KB (4,196 words) - 01:16, 21 March 2025
Wishart distribution (section Cross-entropy)
_{p}\left({\frac {n}{2}}\right)+{\frac {np}{2}}\end{aligned}}} The cross-entropy of two Wishart distributions p 0 {\displaystyle p_{0}} with parameters...
27 KB (4,194 words) - 18:43, 6 April 2025
Neural machine translation (section Cross-entropy loss)
of the factors’ logarithms and flipping the sign yields the classic cross-entropy loss: θ ∗ = a r g m i n θ − ∑ i T log ∑ j = 1 J ( i ) P ( y j ( i...
36 KB (3,901 words) - 13:49, 28 April 2025
Maximum likelihood estimation (section Relation to minimizing Kullback–Leibler divergence and cross entropy)
the relationship between maximizing the likelihood and minimizing the cross-entropy, URL (version: 2019-11-06): https://stats.stackexchange.com/q/364237...
68 KB (9,706 words) - 01:14, 15 May 2025

rare-event simulation. He is, with Reuven Rubinstein, a pioneer of the Cross-Entropy (CE) method. Born in Wapenveld (municipality of Heerde), Dirk Kroese...
5 KB (579 words) - 18:48, 3 December 2024
In statistics and information theory, a maximum entropy probability distribution has entropy that is at least as great as that of all other members of...
36 KB (4,479 words) - 17:16, 8 April 2025
Perplexity (category Entropy and information)
{1}{N}}\sum _{i=1}^{N}\log _{b}q(x_{i})} may also be interpreted as a cross-entropy: H ( p ~ , q ) = − ∑ x p ~ ( x ) log b q ( x ) {\displaystyle H({\tilde...
12 KB (1,865 words) - 13:50, 11 April 2025

expression is identical to the negative of the cross-entropy (see section on "Quantities of information (entropy)"). Therefore, finding the maximum of the...
245 KB (40,562 words) - 12:56, 14 May 2025
is different than the data set used to train the large model) using cross-entropy as the loss function between the output of the distilled model y ( x...
17 KB (2,545 words) - 22:20, 7 May 2025
The ORM is usually trained via logistic regression, i.e. minimizing cross-entropy loss. Given a PRM, an ORM can be constructed by multiplying the total...
24 KB (2,863 words) - 14:16, 19 May 2025
loss function or "cost function" For classification, this is usually cross-entropy (XC, log loss), while for regression it is usually squared error loss...
56 KB (7,993 words) - 09:47, 17 April 2025
interpreted geometrically by using entropy to measure variation: the MLE minimizes cross-entropy (equivalently, relative entropy, Kullback–Leibler divergence)...
13 KB (1,720 words) - 02:18, 19 January 2025

The cross-entropy (CE) method generates candidate solutions via a parameterized probability distribution. The parameters are updated via cross-entropy minimization...
68 KB (8,045 words) - 22:08, 17 May 2025
Multinomial logistic regression (redirect from Maximum entropy classifier)
regression, multinomial logit (mlogit), the maximum entropy (MaxEnt) classifier, and the conditional maximum entropy model. Multinomial logistic regression is used...
31 KB (5,225 words) - 12:07, 3 March 2025
evaluation and comparison of language models, cross-entropy is generally the preferred metric over entropy. The underlying principle is that a lower BPW...
114 KB (11,945 words) - 09:37, 17 May 2025
quantum supercomputer. Alternative benchmarks include quantum volume, cross-entropy benchmarking, Circuit Layer Operations Per Second (CLOPS) proposed by...
4 KB (362 words) - 20:57, 8 May 2025
Battiti, G. Tecchiolli (1994), recently reviewed in the reference book cross-entropy method by Rubinstein and Kroese (2004) random search by Anatoly Zhigljavsky...
12 KB (1,071 words) - 06:25, 15 December 2024

The cross-entropy method (CE) generates candidate solutions via a parameterized probability distribution. The parameters are updated via cross-entropy minimization...
35 KB (4,628 words) - 20:35, 23 April 2025
supervised model. In particular, it is trained to minimize the following cross-entropy loss function: L ( θ ) = − 1 ( K 2 ) E ( x , y w , y l ) [ log ( σ...
62 KB (8,617 words) - 19:50, 11 May 2025
y)\,} Despite similar notation, joint entropy should not be confused with cross-entropy. The conditional entropy or conditional uncertainty of X given...
64 KB (7,976 words) - 13:50, 10 May 2025
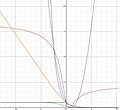
cross-entropy loss (Log loss) are in fact the same (up to a multiplicative constant 1 log ( 2 ) {\displaystyle {\frac {1}{\log(2)}}} ). The cross-entropy...
24 KB (4,212 words) - 19:04, 6 December 2024
through the internet it is known as quantum computing within the cloud. Cross-entropy benchmarking (also referred to as XEB), is quantum benchmarking protocol...
47 KB (5,490 words) - 03:38, 24 April 2025