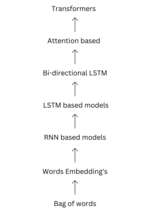
 | A transformer is a deep learning architecture developed by Google and based on the multi-head attention mechanism, proposed in a 2017 paper "Attention... 66 KB (8,256 words) - 18:24, 7 May 2024 |
Mamba is a deep learning architecture focused on sequence modeling. It was developed by researchers from Carnegie Mellon University and Princeton University... 12 KB (1,254 words) - 10:13, 25 April 2024 |
paper "Attention Is All You Need" which introduced the Transformer model, a novel architecture that uses a self-attention mechanism and has since become... 7 KB (542 words) - 15:45, 31 March 2024 |
a {\displaystyle W_{a}} is a learnable weight matrix. Transformer (deep learning architecture) § Efficient implementation Rumelhart, David E.; Mcclelland... 28 KB (2,185 words) - 01:06, 9 May 2024 |
 | supervised, semi-supervised or unsupervised. Deep-learning architectures such as deep neural networks, deep belief networks, recurrent neural networks,... 175 KB (17,448 words) - 12:01, 10 May 2024 |
 | used in natural language processing tasks. GPTs are based on the transformer architecture, pre-trained on large data sets of unlabelled text, and able to... 46 KB (4,098 words) - 16:16, 2 May 2024 |
Multimodal learning, in the context of machine learning, is a type of deep learning using a combination of various modalities of data, such as text, audio... 7 KB (1,746 words) - 10:31, 3 April 2024 |
GPT-3 (redirect from Generative Pre-trained Transformer 3) transformer-based deep-learning neural network architectures. Previously, the best-performing neural NLP models commonly employed supervised learning... 54 KB (4,934 words) - 06:55, 6 May 2024 |
That Transformer (machine learning model), a deep learning architecture Transformer (flying car), a DARPA military project "Electronic transformer", a... 2 KB (222 words) - 22:24, 24 January 2024 |
made available for TensorFlow. Transformer (machine learning model) Attention (machine learning) Perceiver Deep learning PyTorch TensorFlow Dosovitskiy... 22 KB (2,521 words) - 03:31, 4 May 2024 |
Google Brain (redirect from Google deep learning project) present in a photo that a human could easily spot. The transformer deep learning architecture was invented by Google Brain researchers in 2017, and explained... 35 KB (3,833 words) - 11:04, 18 April 2024 |
AI accelerator (redirect from Deep learning accelerator) An AI accelerator, deep learning processor, or neural processing unit (NPU) is a class of specialized hardware accelerator or computer system designed... 54 KB (5,137 words) - 23:57, 10 May 2024 |
T5 (language model) (section Architecture) T5 (Text-to-Text Transfer Transformer) is a series of large language models developed by Google AI. Introduced in 2019, T5 models are trained on a massive... 6 KB (535 words) - 07:55, 12 May 2024 |
Reinforcement learning is one of three basic machine learning paradigms, alongside supervised learning and unsupervised learning. Reinforcement learning differs... 55 KB (6,582 words) - 12:51, 15 April 2024 |
 | mechanisms proposed by Bahdanau et al. into a new deep learning architecture known as the transformer. The paper is considered by some to be a founding... 5 KB (396 words) - 21:58, 30 April 2024 |
Large language model (category Deep learning) capable, as of March 2024[update], are built with a decoder-only transformer-based architecture. Up to 2020, fine tuning was the only way a model could be adapted... 128 KB (11,573 words) - 07:58, 12 May 2024 |
 | adversarial networks (GAN) and transformers are used for content creation across numerous industries. This is because deep learning models are able to learn... 157 KB (16,980 words) - 10:26, 10 May 2024 |
ongoing AI spring, and further increasing interest in ANNs. The transformer architecture was first described in 2017 as a method to teach ANNs grammatical... 61 KB (6,432 words) - 07:45, 10 May 2024 |
Whisper is a weakly-supervised deep learning acoustic model, made using an encoder-decoder transformer architecture. Whisper V2 was released on December... 10 KB (907 words) - 10:25, 20 April 2024 |
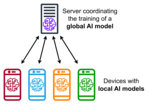 | Things, and pharmaceuticals. Federated learning aims at training a machine learning algorithm, for instance deep neural networks, on multiple local datasets... 51 KB (5,961 words) - 19:19, 23 February 2024 |
Deep reinforcement learning (deep RL) is a subfield of machine learning that combines reinforcement learning (RL) and deep learning. RL considers the... 27 KB (2,935 words) - 05:11, 23 March 2024 |
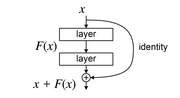 | Residual neural network (category Deep learning) network (also referred to as a residual network or ResNet) is a seminal deep learning model in which the weight layers learn residual functions with reference... 25 KB (2,828 words) - 03:31, 4 May 2024 |
GPT-4 (redirect from Generative Pre-trained Transformer 4) Generative Pre-trained Transformer 4 (GPT-4) is a multimodal large language model created by OpenAI, and the fourth in its series of GPT foundation models... 59 KB (5,620 words) - 22:17, 28 April 2024 |
Bidirectional Encoder Representations from Transformers (BERT) is a language model based on the transformer architecture, notable for its dramatic improvement... 18 KB (2,144 words) - 09:13, 7 May 2024 |
 | modalities through the use of deep neural network architectures such as CNNs and transformers. Supervised feature learning is learning features from labeled data... 45 KB (5,074 words) - 13:50, 20 April 2024 |
| GPT-1 (category Generative pre-trained transformers) Pre-trained Transformer 1 (GPT-1) was the first of OpenAI's large language models following Google's invention of the transformer architecture in 2017. In... 32 KB (1,064 words) - 15:45, 8 May 2024 |
Q-learning algorithm. In 2014, Google DeepMind patented an application of Q-learning to deep learning, titled "deep reinforcement learning" or "deep Q-learning"... 29 KB (3,785 words) - 06:23, 6 April 2024 |
Multilayer perceptron (category Neural network architectures) successes of deep learning being applied to language modelling by Yoshua Bengio with co-authors. In 2017, modern transformer architectures has been introduced... 16 KB (1,922 words) - 04:17, 29 March 2024 |
 | GPT-2 (redirect from Generative Pre-trained Transformer 2) GPT-4, a generative pre-trained transformer architecture, implementing a deep neural network, specifically a transformer model, which uses attention instead... 45 KB (3,316 words) - 15:23, 30 April 2024 |
performance of their model. If deep learning is used, the architecture of the neural network must also be chosen by the machine learning expert. Each of these... 8 KB (943 words) - 07:23, 11 February 2024 |